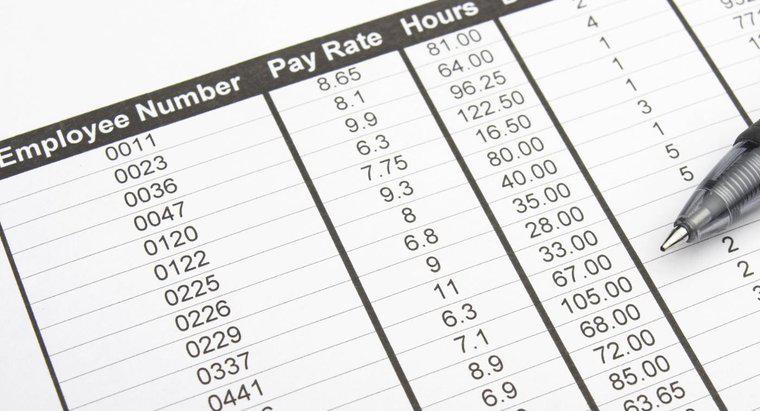
Podstawową cechą relacyjnej bazy danych jest jej klucz podstawowy, który jest unikalnym identyfikatorem przypisanym do każdego rekordu w tabeli. Przykładem dobrego klucza podstawowego jest numer rejestracyjny. Dzięki temu każdy rekord jest unikalny, co ułatwia przechowywanie danych w wielu tabelach, a każda tabela w relacyjnej bazie danych musi zawierać pole klucza podstawowego.
Inną kluczową cechą relacyjnych baz danych jest ich zdolność do przechowywania danych w wielu tabelach. Ta funkcja pokonuje ograniczenia prostych baz danych plików, które mogą mieć tylko jedną tabelę. Rekordy bazy danych przechowywane w tabeli są powiązane z rekordami w innych tabelach za pomocą klucza podstawowego. Klucz podstawowy może dołączyć do tabeli w relacji jeden do jednego, relacji jeden do wielu lub relacji wiele do wielu.
Relacyjne bazy danych umożliwiają użytkownikom usuwanie, aktualizowanie, odczytywanie i tworzenie wpisów danych w tabelach bazy danych. Jest to realizowane za pomocą strukturalnego języka zapytań lub SQL, opartego na relacyjnych zasadach algebraicznych. SQL umożliwia także użytkownikom manipulowanie danymi w relacyjnej bazie danych i ich wyszukiwanie.
Tabele relacyjne są zgodne z różnymi regułami integralności, które zapewniają, że przechowywane w nich dane są zawsze dostępne i dokładne. Reguły w połączeniu z SQL umożliwiają użytkownikom łatwe egzekwowanie kontroli transakcji i współbieżności, gwarantując w ten sposób integralność danych. Koncepcja relacyjnej bazy danych została opracowana przez Edgara F. Codda w 1970 roku.